Form内にsubmitボタンが2つあったらどうする?
submitボタンのおさらい
皆さんはForm内にあるsubmitボタンをどのように制御していらっしゃるでしょうか。 ボタンのような形をしているので、button要素と同様clickイベントのリスナーを設定して、対応するイベントハンドラで動作させると思いがちですが、そもそも、submitボタンはForm内にあってForm内のinput要素、textarea要素、select要素のvalue属性を集めてFormのaction属性に設定されたエンドポイントに送ることがデフォルトの動作となっています。 したがって、イベントリスナーの設定は当然に予定されているものではないのです。 もちろん、Formの機能としてはデータをエンドポイントに送るだけではないので、それ以外の動作をさせるためにはイベントリスナーは必要ですが、その場合でもsubmitボタンにclickイベントのリスナーを設定するのではなく、FormにonSubmitイベントリスナーを設定すべきだと思います。 ChatGPTにも意見を聞いてみました。
formの送信に関するイベントリスナを設定する場合、onSubmitをform要素に設定することが一般的に推奨されます。以下は、その理由を示すいくつかのポイントです: 全体性: onSubmitはフォーム全体の送信に関するイベントです。ユーザーがsubmitボタンをクリックするだけでなく、例えばフォームのテキストフィールド内でEnterキーを押すことによってもフォームが送信されることがあります。onSubmitは、これらすべての送信方法をカバーします。 バリデーション: フォームのデータバリデーションは一般的に送信前に行われます。onSubmitを使用すると、送信が行われる前にバリデーションを行い、必要に応じて送信を中止することが簡単にできます(event.preventDefault()を使用)。 セマンティクス: formのonSubmitは、フォームが送信されるというセマンティクス(意味)を持っています。このため、その目的に合わせてこのイベントを使用するのは自然です。 柔軟性: 複数のsubmitボタンが1つのフォーム内に存在する場合、それぞれのボタンにonClickリスナーを追加するよりも、フォーム全体にonSubmitリスナーを1つ追加する方が管理が簡単です。
ボタンが2つあったら?
しかし、Form内にsubmitボタンが2つあったらどうするのでしょうか? 入力内容を確認するようなFormがあるとすると、OKかキャンセルを選択するために2つのsubmitボタンがあるというのが一般的です。 この場合どちらのボタンがクリックされたか峻別する必要があります。 FormのonSubmitリスナーは1つしか設定できません。 では、それぞれのボタンにイベントリスナーを設定するしかないのでしょうか?
そんなことはありません。
FormのonSubmitリスナーでコールバックされるイベントハンドラは引数を渡してくれます。 この引数はオブジェクトになっていて、クリックされたボタンの情報も持っているのです。 そのため、これを利用すれば、次のようにボタンを制御できます。 Reactコンポーネントであれば、次のようになります。
const handleSubmit = (e) => {//⓵
e.preventDefault();//⓶
const click_id = e.nativeEvent.submitter.id;//⓷
if (click_id === send_id) {
console.log('ok');
} else if (click_id === cancel_id) {
console.log('cancel')
}
};
return(
<form onSubmit={handleSubmit}>
<input type="submit" id="btn_id_ok" value="ok">
<input type="submit" id="btn_id_cancel" value="cancel">
</form>
)
⓵の行のeが、その引数です。
まず、⓶でpreventDefaultメソッドを使ってonSubmitのデフォルトの挙動を止めます。
そして、③ではクリックされたボタンについているidを取り出すことができます。
これが取得できれば、ハンドラの中で条件分岐による制御が可能になります。
ここではnativeEvent.submitterというオブジェクトが利用できるということを覚えておきましょう
jQueryではオブジェクトが違う
先に示した例はReactコンポーネントをjsxの記法でjsファイルに記述しました。 では、これをjQueryで書くとどうなるでしょうか。
<script type="text/javascript" src="https://ajax.googleapis.com/ajax/libs/jquery/3.6.0/jquery.min.js"></script>
<form>
<input type="submit" id="btn_id_ok" value="ok">
<input type="submit" id="btn_id_cancel" value="cancel">
</form>
<script>
const send_id = "btn_id_ok";
const cancel_id = "btn_id_cancel";
$('form').on('submit', function (e) {
e.preventDefault();
const click_id = e.nativeEvent.submitter.id;//⓵
if (click_id === send_id) {
console.log('ok');
} else if (click_id === cancel_id) {
console.log('cancel');
}
});
</script>
これで同じ動きになるかと思いきや、そうなりません。なぜなら、イベントハンドラに渡ったeがReactの場合と違うからです。
結論から言うとe.nativeEvent.submitter.id;ではなくe.originalEvent.submitter.id;となります。
なぜ、こんな違いが生じるのか、ChatGPTに聞いてみました。
jQuery: jQueryは既存のJavaScriptイベントを包括する独自のイベントオブジェクトを作成します。このオブジェクトはネイティブのイベントオブジェクトを包含していて、それにアクセスするためにはe.originalEventプロパティを使用します。このようにして、jQueryはクロスブラウザの互換性を提供しています。
React: Reactは仮想DOMという概念を導入しており、実際のDOMとは異なるレベルの抽象化を提供しています。Reactも独自のイベントシステムを持っており、これはSyntheticEventシステムと呼ばれます。しかし、Reactはネイティブのイベントオブジェクトにアクセスするための方法も提供しており、それがe.nativeEventプロパティを使用する方法です。
これを読んで思い出しました。
"The React Way"という言葉です。
この言葉の意味を短く要約すると、
jQueryはDOMを直接操作してレンダリングするのに対し、Reactは状態変数を介して仮想DOMを生成し、実態のDOMとの差分をレンダリングすることを原則としつつもDOMの直接操作の方法も残しているということです(この話題については、こちらのブログで解説してますので、興味のある方はご覧ください。)。
つまり、jQueryにとっては.オリジナルな手法、すなわちoriginalEventなのですが、Reactにとっては、もとからあったネイティブな手法、すなわちnativeEventというわけなんだと理解しました。
こんなところにも"The React Way"という考え方が反映されているということが非常に興味深いと思いませんか。
まとめ
それはさておき、今回の結論をまとめておきます。
- submitはそれ自体にイベントリスナを設定するのではなく、formのonSubmitイベントリスナでクリック時の処理をすることが推奨される。
- ReactコンポーネントでonSubmitイベントリスナを設定したとき、イベントハンドラに渡される引数からはnativeEvent.submitterというオブジェクトでクリックされたsubmitを峻別することができる。
- jQeryでは$('form').on('submit',function(e){・・・})としたときのイベントハンドラに渡される引数からはoriginalEvent.submitterというオブジェクトでクリックされたsubmitを峻別することができる。
とりあえず、この3つを覚えておくとFormの操作に迷うことがなくなりそうです。
Reactの仮想DOMが理解できてなかった!?
Reactを始めると仮想DOMという言葉を耳にするようになります。 ChatGPTの説明です。
生成: Reactコンポーネントがレンダリングされるとき、仮想DOMツリーが生成されます。これは実際のDOMツリーの軽量な表現です。 差分検出: 状態やpropsの変更によりコンポーネントが再レンダリングされると、新しい仮想DOMツリーが生成され、前回のツリーと比較されます。 再調整 (Reconciliation): 2つの仮想DOMツリーの差分を検出し、変更が必要な部分だけを特定します。 実際のDOM更新: 差分検出を通じて得られた変更のみが、効率的に実際のDOMに適用されます。 この仕組みにより、Reactは不必要なDOM操作を避け、高速なUI更新を実現しています。
文書で表現するとわかりにくいです。 ちょっと図式化してみましょう。
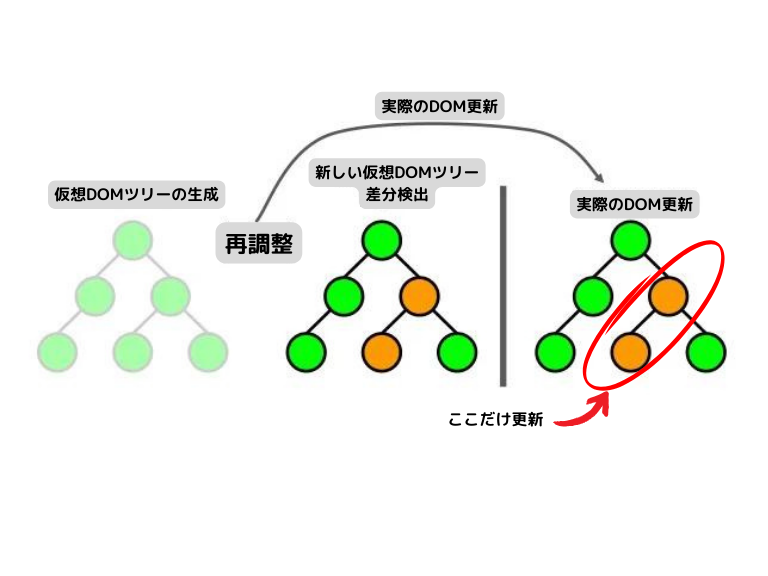
これでなんとなくわかった気になります。 実際、この程度の説明で十分なことが多いと思います。 しかし、この程度の説明だと実際に起きた不具合が、その仕組みを十分に理解していないことが原因だと気が付かず、時に相当深い奈落に落ちていくことになります。 そうならないように、この際、私の体験を材料にして、Reactの仮想DOMによるレンダリングの仕組みを深堀して徹底理解しましょう。
ハマったきっかけはGoogle Code Prettify
皆さんはGoogle Code Prettifyというライブラリをご存じでしょうか? ブログなどでコードを紹介するとき、ハイライト表示するために使います。 コードをハイライト表示させるライブラリは他にもあると思いますが、これはかなりメジャーなライブラリで使い勝手がいいのです。
そこで、これを使ったWordpressのブロックを作ろうと思い制作にかかりました。 このサイトでも紹介されていたので参考にさせてもらいました。
概ねできたのですが、不具合が出ています。
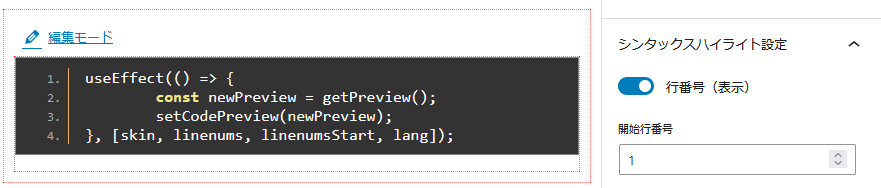
右のトグルボタンで行番号を表示したり、非表示にしたりできるはずでした。

しかし、非表示にはならず、何度かトグルボタンをクリックすると、行番号がどんどん重なっていきます。
Google Code Prettifyの仕組み
なぜ、このような現象が起きるのかは、Google Code Prettifyの仕様を調べたらすぐにわかりました。 今回の説明のためにGoogle Code Prettifyについて、ごく簡単に、このライブラリの仕組みを説明します。 ライブラリを使用する側は次のようなHTMLを用意します。
<pre class="prettyprint linenums" >
code Hilight
</pre>
そして、このHTMLをReactコンポーネントとしてレンダリングした後、useEffectで
useEffect(() => {
PR.prettyPrint();
}, []);
としてやれば、先ほど用意したHTMLから自動的に次のようなDOMツリーを生成してくれます。
<pre class="prettyprint linenums prettyprinted">
<span class="pln">code </span>
<span class="typ">Hilight</span>
</pre>
このようにクラス付きのDOMツリーを生成することで、別に用意されたCSSが当たって、きれいなハイライトが表示されるわけです。 (今回の説明ではライブラリを読み込む部分の説明は省略しています。一からライブラリを読み込んで実装したい方は、このブログが参考になると思います。)
ところが、このようにきれいにラッピングしてくれるのは、pre要素の中味がテキストになっている状態で
PR.prettyPrint();
が実行される必要があります。 しかし、すでにpre要素の中味がDOMツリーになっていると、そのDOMツリーの最初のDOM要素の下に新たなツリーを作ってしまいます。 これが、今回起きた不具合の原因です。
再レンダリングでDOMツリーはもとのテキストにもどる?
だったら、最初に用意したHTMLを再レンダリングさせればいいんじゃないのか思いますよね。 ある程度Reactを習熟した方なら誰しもそう思うのではないでしょうか。 では、実際にコードにしてみましょう。
export default function Component() {
const [isLine, setIsLine] = useState('');//⓵
const code = 'line 1\nline 2'//⓶
useEffect(() => {//⓷
PR.prettyPrint();
}, [isLine]);
return(
<button onClick={() => setIsLine('linenums')}>//⓸
render
</button>
<pre class="prettyprint {isLine}" >//⓹
{code}//⓺
</pre>
)
}
⓵では状態変数isLineを用意します。 ⓶ではレンダリングするコードをcodeという変数内にセットして⓺でレンダリングさせるようにします。 ⓷はコンポーネントマウント時とisLineの更新時に発火するuseEffectです。 ⓸でボタンを押せばisLineが更新され、再レンダリングが起き、その後⓷のuseEffectが実行されます。
これでpre要素にはlinenumsクラスが付加されて行番号付きのシンタックスハイライトが現れるというシナリオを期待しているのですが、このシナリオは実現しません。
その理由は⓺の再レンダリングが実行されないからです。
⓺は'line 1\nline 2という文字列でした。しかし、コンポーネントがマウントされたとき⓷のuseEffectが発火してPR.prettyPrint();が実行されたため、DOMツリーに変容しています(useEffectは依存配列の更新時だけでなく、コンポーネントのマウント時にも実行される。)。
だから、isLineを更新することで、もう一度DOMツリーがもとのテキストに戻った上で、PR.prettyPrint();が実行されると考えたのです。
しかし、そうはならないのです。
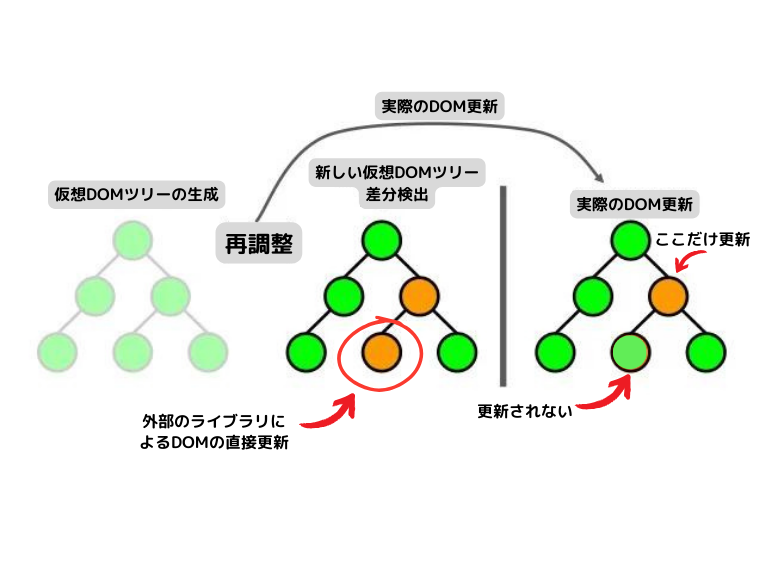
なぜなら、そこにはReactの仮想DOMによる比較に基づいた変更内容の決定というプロセスが働くためです(これを"reconciliation"(調整)と呼ぶそうです。)。
⓺の部分は外見上変化していますが、それはReactが知らないところで外部のライブラリ(Google Code Prettify)がDOM要素を直接更新したものであって、React側から見れば、テキストのままのはずなのです。
したがって、仮想DOMには差分が生じておらず、再レンダリングの対象から除外されてしまいます。
その結果、pre要素にはisLineという状態変数が変化したことによってクラスが追加されるというレンダリングは起きますが、⓺の部分は外部ライブラリによって更新されたままの状態になります。
この状態でPR.prettyPrint();が実行されると、先に示した奇妙な現象が起きるわけです。
手動で元に戻すしかない
では、どうするのか? 結論としては手動で元に戻すしかありません。 Google Code PrettifyにはDOMツリーを元のテキストに戻すという機能はないでしょう。 手動といっても、それほど手間がかかるわけではありません。 コードを示します。
export default function Edit() {
const [isLine, setIsLine] = useState('');
const preRef = useRef(null);//⓵
const code = 'line 1\nline 2'
useEffect(() => {
if (!preRef.current.classList.contains('prettyprinted')) {
preRef.current.innerText = code;//⓶
}
PR.prettyPrint();
}, [isLine]);
return (
<>
<button onClick={() => setIsLine('linenums')}>
render
</button>
<pre ref={preRef} class={`prettyprint ${isLine}`} >//⓷
{code}
</pre>
</>
)
}
⓵でuseRefを宣言し、⓷でpre要素を参照しておきます。 ⓶でその参照を使用してinnerTextプロパティをもとにもどしてやります。 その後、PR.prettyPrint()が実行されることになるので、期待どおりのレンダリングが実行されます。
まとめ
今回は仮想DOMの仕組みを理解していないと、再レンダリングされるはずなのになぜ再レンダリングがおこならないのか、見当がつかないという状況になるということをお伝えすることに焦点を絞りました。 そのため、Google Code Prettifyの使い方や、useRefの利用のところは、それほど説明を加えませんでした。useRefは非常に重要なReactのフックスですので、他のブログで詳しく説明したいと思います。
Reactには仮想DOMによるレンダリングという仕組みがあることは、多くの技術者が意識していることだと思いますが、その実態を目の当たりにすることは少ないのではないでしょうか。 レンダリング後のDOM要素を開発者ツールで確認しても、それが再レンダリングされた結果なのか、再レンダリングされなかったのか見分けがつかないし、確認する必要性に迫られることが少ないからです(本当はプラグイン等で不要なレンダリングが起きていないかチェックすべきなんでしょうね。)。 しかし、今回のような不具合が起きるとそうはいきません。 外部ライブラリの利用は実践的なコンポーネントを作る上で欠かせない存在です。それとReactをうまく組み合わせるためには、基本の徹底理解がいかに大事か身につまされました。
このブログが少しでもお役に立てば光栄です。
マージンの折り重ね(マージンの重複)って知ってた?
Gutenbergのブロック開発をしていて、おかしな現象に見舞われました。次の画像をご覧ください。


これはブロックにニューモフィズムというシャドーをつけたものです。 上がブロックエディタの表示で、下がフロントエンドの表示です。 ご覧のとおり下は高さが狭く、ニューモフィズムの浮き出た感じが出し切れていません。 なぜ、こんな現象が起こるのかをブログにしたいと思います。
この画像のHTMLとCSSについて
まず、この画像のHTMLとCSSを示します。 まず、HTMLです。
<div>
<ul>
<li>情報入力</li>
<li>確認</li>
<li>処理完了</li>
</ul>
</div>
次にCSS(SCSS)です。
div{
ul{
margin: 1em 2em 1em 2em;
padding: 1em 2em 1em 2em;
box-shadow: 5px 5px 5px #ecd4d4,-5px -5px 5px #fcf8f8;
}
}
簡単なコードです。div要素でul要素をラップし、ul要素にはmarginとpaddingをつけました。 その上でbox-shadowをつければ、marginとpaddingの間にシャドーが落ちてくれると思ったわけです。 しかし、ブロックエディタは思惑どおりでしたが、肝心のフロントエンドは変な表示になってしまいました。
margin-topとmargin-bottomにはマージンの折り重ね(マージンの重複)という現象がある
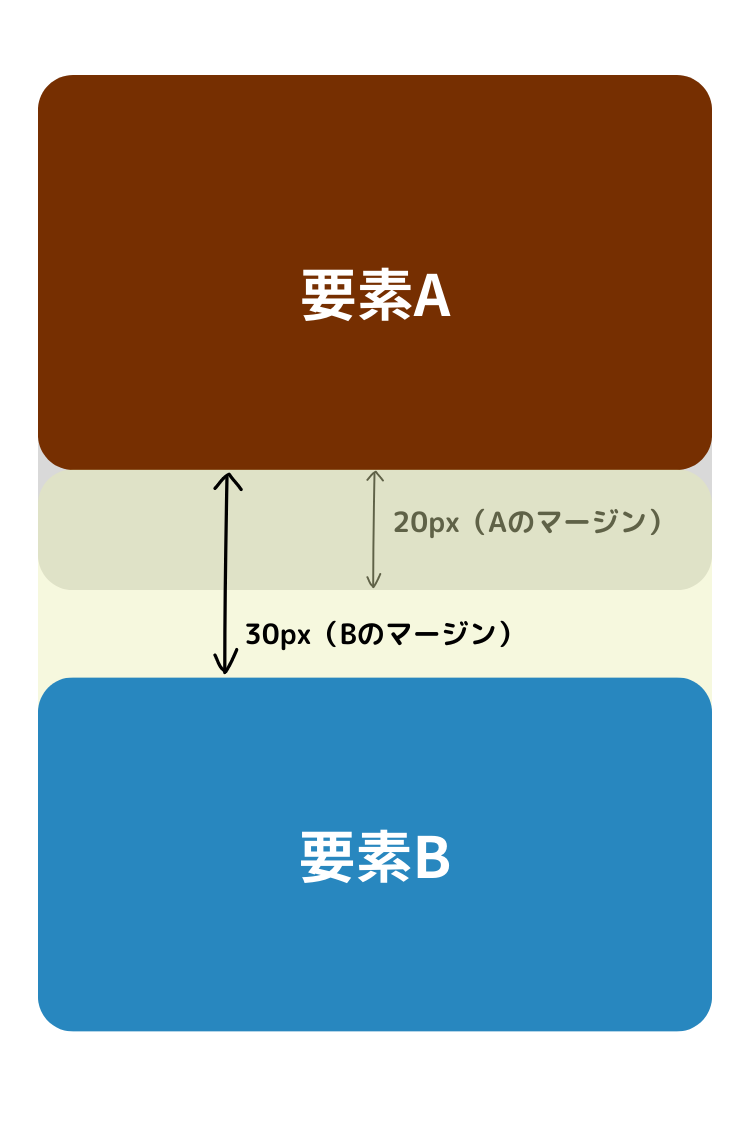
調べてみるとこんなことがわかってきました。 margin-topとmargin-bottomというのは、上下に接触する要素同士においては、折り重なるという性質があります。 次のようなコードでは、要素Aの margin-bottom と要素Bの margin-top が折り重ねられ、実際のマージンは30px(大きい方の値)となります。
<div style="margin-bottom: 20px;">要素A</div> <div style="margin-top: 30px;">要素B</div>
この事例は隣接する兄弟要素の場合ですが、この現象は、親要素とその最初または最後の子要素の間でも発生します。
<div style="margin-bottom: 20px;">
要素A
<div style="margin-top: 30px;">要素B</div>
</div>
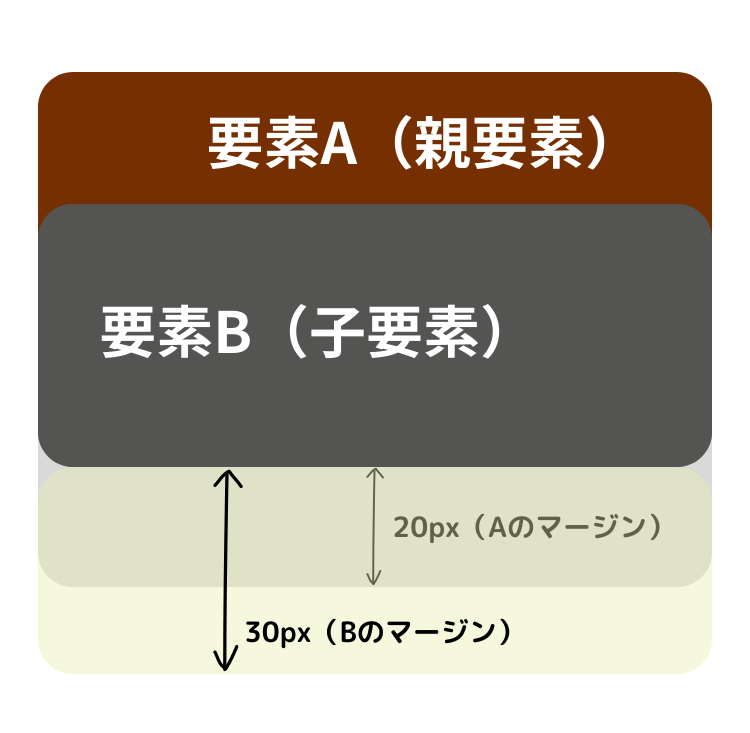
この図のように子要素の上側・下側のマージンは親要素の外に「押し出される」ことになり、親要素の縦幅を広げるわけではないのです。 これが「マージンの折り重ね(マージンの重複)」です。
親要素に border や padding が付いているとこの現象は起こらない
では、なぜブロックエディタの方は、期待どおりの動きをしてくれるのかということです。 実はGutenbergのブロック開発ではブロックエディタ側には、ブロックに1pxの破線のボーダーが付いています。 これのおかげで子要素のマージンは親要素のボーダーの内側に回るのです。 コードと図解は次のようになります。
<div style="
margin-bottom: 20px;
border: 1px dotted #f00;
">
要素A
<div style="margin-top: 30px;">要素B</div>
</div>
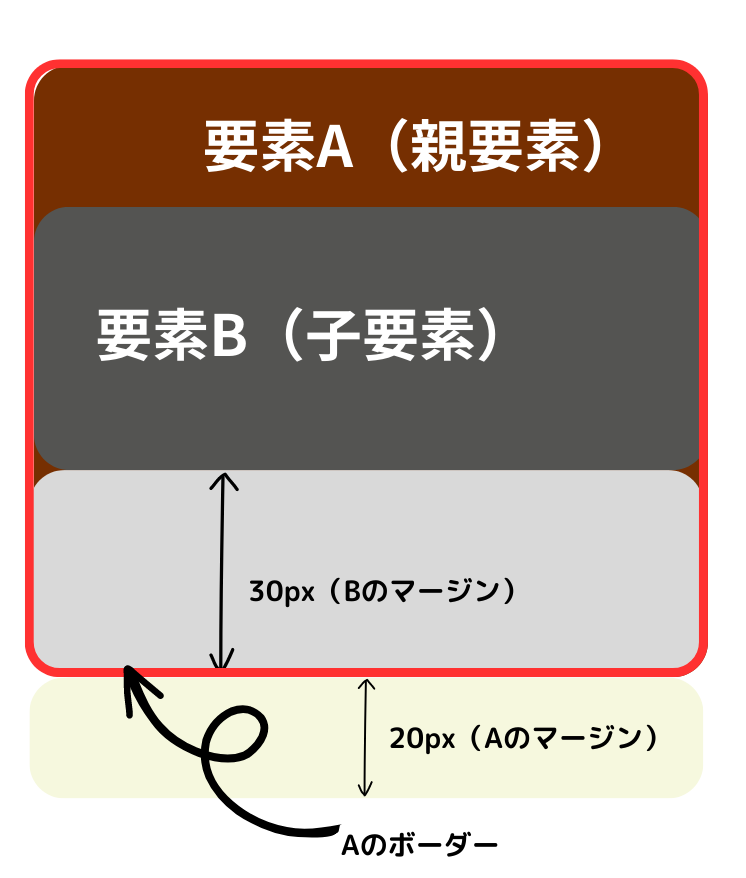
これは親要素にパディングがある場合でも同じです。 その他にも「マージンの折り重ね」が起きない場合があるので、箇条書きにしてまとめます。
- borderやpaddingの追加:親要素に少なくとも1pxの border や padding がある。
- overflowプロパティの使用:親要素に overflow: auto または overflow: hidden を設定する。
- flexboxやgridの使用:FlexboxやGridレイアウトを使用する。
幅(margin-left および margin-right)についてはどうなのか
ちなみに、水平方向のマージン(margin-left および margin-right)には、マージンの折り重ね(マージンの重複)という現象は存在しません。 そもそも、水平方向のマージンというのは、要素を親要素のどの位置に配置されるかを決定するためのもので、親要素の全体の幅そのものを広げるという効果はありません。 仮に、水平方向のマージン(margin-left および margin-right)が自らの幅とあわせて、親要素の幅を超えるとオーバーフローを起こします。
親要素の幅に影響を与えるのは子要素のwidthやpadding, borderなどのプロパティです。子要素の幅やパディング、ボーダーが親要素の利用可能な幅を超える場合、通常、親要素は子要素を収容するために拡張されます。 ただし、親要素に固定の幅が設定されている、あるいは他のスタイルが適用されている場合はそうならないこともあります。
まとめ
CSSの基本中の基本とも言えるmarginプロパティですが、実はこんなに奥が深かったということを今更のように知りました。
皆さんはいかがでしょう。
もし、私が経験したような現象でお悩みの方がいれば、是非参考にしていただきたいと思います。
セットしたはずのグラデーションが表示されない?!
まずはPanelColorGradientSettingsを使ってみよう
ブロック開発でカスタムブロックに色を設定するのは基本中の基本ですよね。 まず、最初のカスタマイズは色の設定でしょう。 Wordpressはそのための入力用コントロールとしてPanelColorGradientSettingsというコントロールを用意してくれています。 これが優れもので、中間色はもちろんのこと、グラデーションまでセットできます。 これを使うようになってグラデーションを採用することが増えました。
このコントロールを使って、単色でもグラデーションでも選択できるようにするには、次のような手順を踏みます。 1. 色情報を格納するためにblock.json内にattributesを設定する。 2. サイドバーにPanelColorGradientSettingsを設置する。 3. ユーザーが選択した色をbackGroundスタイルにセットする。
具体的なコードで見てみましょう。 まず、block.jsonにこんなふうに入れます
"attributes": {
"bg_Color": {
"type": "string",
"default": "#504237"
},
"bg_Gradient": {
"type": "string",
}
}
attributesには初期値も設定できるんです。ですから、このように設定すると、最初にブロックがマウントされてattributesが呼び出されるとbg_Colorには#504237がセットされた状態になるのです。便利なので重宝します。
つぎにPanelColorGradientSettingsの設置です。
edit.jsのreturn文にInspectorControlsを用意してその中に次のコードを入力してやります。
<PanelColorGradientSettings
title={__("Background Color Setting","text-domain")}
settings={[
{
colorValue: bg_Color,
gradientValue: bg_Gradient,
label: __("Choice color or gradient","text-domain"),
onColorChange: (newValue) => {
setAttributes({ bg_Color: newValue });
},
onGradientChange: (newValue) => {
setAttributes({ bg_Gradient: newValue });
},
}
]}
/>
これで取得したプロパティ値をDOM要素のstyle属性としてセットすればあっという間にインラインスタイルが出来上がります。 次のような感じです。
const bgColor = bg_Color || bg_Gradient;
return(
<div style={{ backGround: bgColor }}></div>
)
なんとも小気味よくセットできるのです。
グラデーションが表示されない
しかし、ふと見るとこんな現象が起こっています。
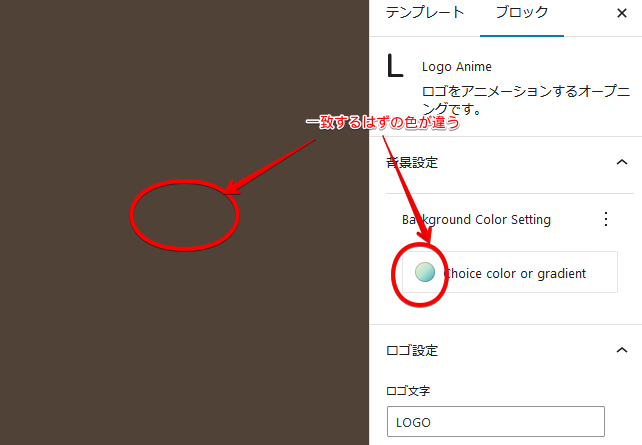
お判りでしょうか。サイドバーには確かに選択したグラデーションが表示されているのに、レンダリングされたブロックは単色です。 この色はデフォルトで設定した色です。 なぜ、こんなことが起こるのか全く分かりません。
そしてさらにsave.jsに
<div style={{ background: bgColor }}></div>
などとするとBlock validation failedというエラーを起こします。これはエディタでブロックが保存された状態と、それをレンダリングしようとする状態とで一致しない場合に発生します。リカバリを試みることはできますが、毎回そんなことをしているわけにはいかないし、実際リカバリもできもせん。
途方に暮れてしまいました。
原因の解明
何とか原因が究明できましたので、ここでそれを解説します。
PanelColorGradientSettingsは単色を選択するとその色のコードを、グラデーションを選択するとlinear-gradientまたはradial-gradientを返します。そして選択しなかった方はundefinedを返すのです。 つまり、単色が選択されると、bg_Colorには色コードがセットされますが、グラデーションが選択されるとundefinedがセットされます。 この仕組みが元凶でした。 もう少し具体的に説明します。 グラデーションを選択したとします。 セットしたときはbg_Colorにundefinedがセットされ、bg_Gradientには、linear-gradientまたはradial-gradientがセットされます。 そして、
const bgColor = bg_Color || bg_Gradient;
が実行されれば、無事にbgColorにはグラデーションのスタイルがセットされ、ブロックにはグラデーションがレンダリングされます。
しかし、その状態でブロックが保存され、次にそのブロックがマウントされるとどうなるでしょうか。
ここで、あの重宝していた初期値の設定が仇になります。
bg_Colorはundefinedのままでいてくれません。attributesで設定した初期値である#504237がセットされるのです。そしてconst bgColor = bg_Color || bg_Gradient;が実行されるとbgColorには bg_Colorがセットされてしまって bg_Gradientは無視されてしまいます。
これが、奇妙な現象の原因でした。
対策を講じたコード
そしてようやく結論です。
<PanelColorGradientSettings
title={__("Background Color Setting")}
settings={[
{
colorValue: bg_Color,
gradientValue: bg_Gradient,
label: __("Choice color or gradient"),
onColorChange: (newValue) => {
setAttributes({ bg_Color: newValue === undefined ? '' : newValue });
},
onGradientChange: (newValue) => {
setAttributes({ bg_Gradient: newValue });
},
}
]}
/>
おわかりでしょうか。onColorChangeのコールバック関数のsetAttributesでセットする値をnewValueがundefinedの場合、つまり、選択されなかった場合は空文字にするのです。undefinedでなければ、初期値のセットは行われません。
そして空文字はfalsy values(falseと評価される値)なのでconst bgColor = bg_Color || bg_Gradient;ではbg_Gradientが選択されるというわけです。
前にattributesに色を設定するときは、初期値の設定には注意しないといけないというようなことを聞いた記憶があるのですが、その時はその意味も理解せずスルーしていました。 しかし、こんなしっぺ返しを食らうとは思ってもみませんでした。
「Reactの方法」に沿ったプログラミングとは
今や、ReactはJavaScriptの中心的な地位を占めるようになったと感じるときがしばしばあります。TypeScriptのように、さらに新しいプログラミング技法は生まれてきていますが、基本の考え方はReactです。 それに対して従来のJavaScriptはプログラミングそのものの考え方が違い、別の言語のように感じます。そのためReactを使いながら従前のJavaScriptのようなプログラミングをすると、「それは「Reactの方法」("The React Way")に沿ったものではありません。」と言われてしまいます。 そもそも、"The React Way"とはなんでしょうか。最近、その意味が少しわかった気がしますので、このブログにまとめておきたいと思います。 なお、従前のJavaScriptのコードはjQueryを導入していることを前提とさせていただきます。
両者の違いの概要
次の図をご覧ください。
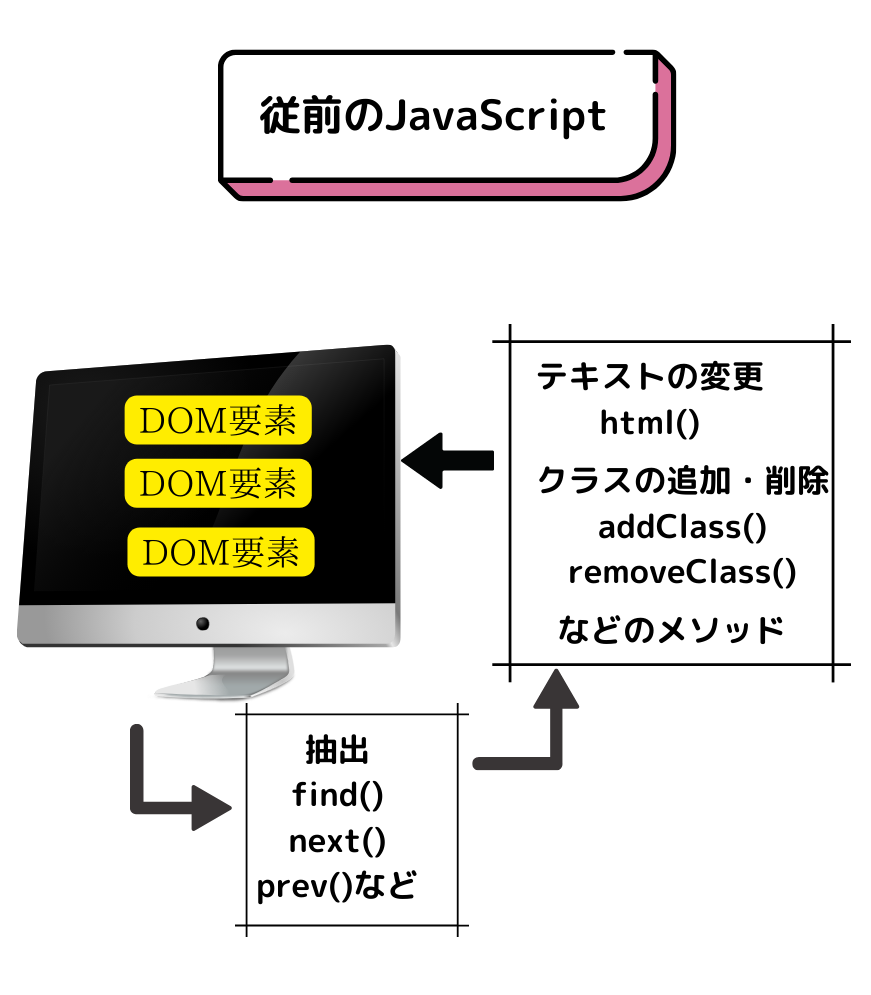
従前のJavaScriptは、DOM要素があって、それを抽出してその要素が持っているテキストや属性の情報を書き換えて再レンダリングしていました。
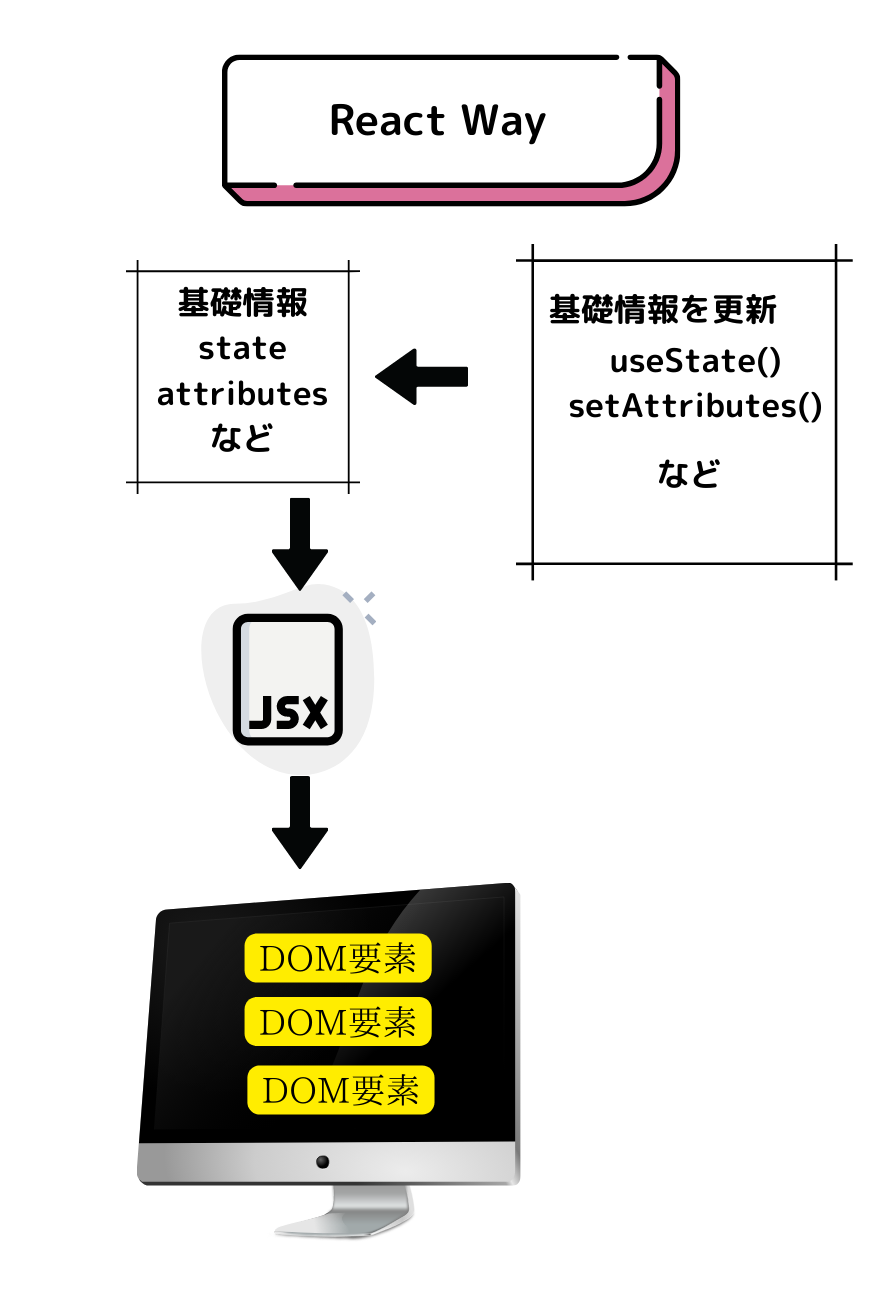
これに対してReactでは、まずDOM要素をレンダリングするための基礎情報というのが存在します。その情報を元にJSXという記法でDOM要素を生成し、レンダリングします。更新するのはDOM要素ではなく、基礎情報の方なのです。JSXというのはHTMLにJavaScriptの変数や条件文を記述できる記法で、HTMLに変数が埋め込まれたような記述になります。
従前のJavaScriptの記法を”imperative”、日本語でいうと「命令的」といい、Reactを"declarative"、日本語でいうと「宣言的」と言ったりもするようです。
実際のコードを比較
実際のプログラミングの場面では”imperative”と"declarative"では、レンダリング結果は同じでも、コードの違いは大きいです。 ここで誤解がないように説明しますが、Reactでも”imperative”な記法は可能だということです。”imperative”と"declarative"はあくまで記法の問題で、言語の仕様を縛っているものではありません。 そのため、今回はより違いが明確になるように、Reactで”imperative”なアプローチと"declarative"なアプローチのコードを示します。
”imperative”なアプローチ
まず、”imperative”なコードを示します。
export function NomalSelect() {
//オプションの一覧を開く
const openClick = (event) => {
const element = event.currentTarget;//⓶
if (element.classList.contains('open')) {//⓷
element.classList.remove('open');
} else {
element.classList.add('open');
}
}
return (
<div onClick={openClick}>//⓵
クリック
</div>
);
}
①はJSXでDOM要素にイベントリスナーをセットしています。
そしてイベントが発生するとopenClickハンドラが発火します。
②でeventオブジェクトからクリックされたオブジェクトを取得します。
③以下でJavaScriptのaddメソッド、removeメソッドでクラスをつけたり外したりしています。
このプログラミングは、DOM要素を取得し、それを直接操作して再レンダリングを起こすというまさに”imperative”なアプローチです。
"declarative"なアプローチ
次に、”declarative”なコードを示します。
export function NomalSelect() {
// open状態を管理するstate
const [isOpen, setIsOpen] = useState(false);//⓷
//オプションの一覧を開く
const openClick = () => {//⓸
// isOpenの値をトグルする
setIsOpen(!isOpen);
}
return (
<div
onClick={openClick}//⓵
className={`${isOpen ? 'open' : ''}`}//⓶
>
クリック
</div>
);
}
①はJSXでDOM要素にイベントリスナーをセットするのはおなじです。
②の部分でJSXの記法を使って3項演算子による条件式でクラス名をセットしています。つまり、状態変数isOpenがtrueならクラス名openをつけてfalseなら空のクラスにするという処理です。
③は、その判断のための状態変数isOpenをuseStateでセットしています。
④以下の処理は状態変数isOpenを更新しています。ここで重要なのはDOM要素を操作しているのではないということです。
まとめ
”imperative”なアプローチと"declarative"なアプローチの違いを、実感していただけたでしょうか?
一番大きな違いは状態変数isOpenがあるかないかです。これが最初に説明した「基礎情報」です。今回はuseStateで管理する状態変数でしたが、Gutenbergのブロックの場合はブロックの属性(attributes)になることもあります。
従前のJavaScriptでは、「基礎情報」なしにDOMをレンダリングしてきたので、これに慣れ親しんだ方は"declarative"なアプローチには違和感を感じるのではないかと思います。私もその一人です。
しかし、"declarative"なアプローチは大きなメリットをもたらします。「基礎情報」の変化によって、再レンダリングが必要なDOM要素が複数あった場合を想像してください。
従来のJavaScriptでは再レンダリングしなければならないDOM要素を全て抽出し、適切なメソッドを選んで属性等を更新します。
ReactならJSXの定義で一元的に管理できるのが最大の利点です。それによって「基礎情報」を更新するだけで全てが再レンダリングされるのです。規模の大きなWebサイトでは保守性が格段の差が出てくると思います。
しかし、何でも"declarative"なアプローチがよいというわけではありません。。特定のユースケース、特にサードパーティのライブラリやフレームワークとの統合においては、直接のDOM操作が必要となる場合もあります。
そのため、Reactにおいても”imperative”なアプローチの方法は覚えておく必要はあると思います。
ブロックの国際化対応は大変な苦難の道のりだった!
WordPressは翻訳関数というのを用意していて、それを使えばpoファイル、moファイルによってタイトルや説明文を多国籍言語で表示させることができます。
これはWordPressを使うWeb制作者の多くが認識していらっしゃるでしょう。
もちろん私もそうでした。
でも、具体的にコーディングしたことはなく、まあその内と思っていたのです。
ひな型からimport { __ } from '@wordpress/i18n';とライブラリがインポートされているぐらいだから、手軽に使えるものと思い込み、いつでもマスターできると思っていました。
しかし、とんでもなかったです。3日かかってやっとなんとか翻訳言語が表示できるようになりましたが、とにかく苦労しました。
このノウハウを決して忘れないようにしたいと思うし、これからチャレンジする方には、少しでも苦労せず身に着けていただけたらいいという思いでブログにします。
POT、PO、MOの各ファイルの役割
まず、この図をご覧ください。
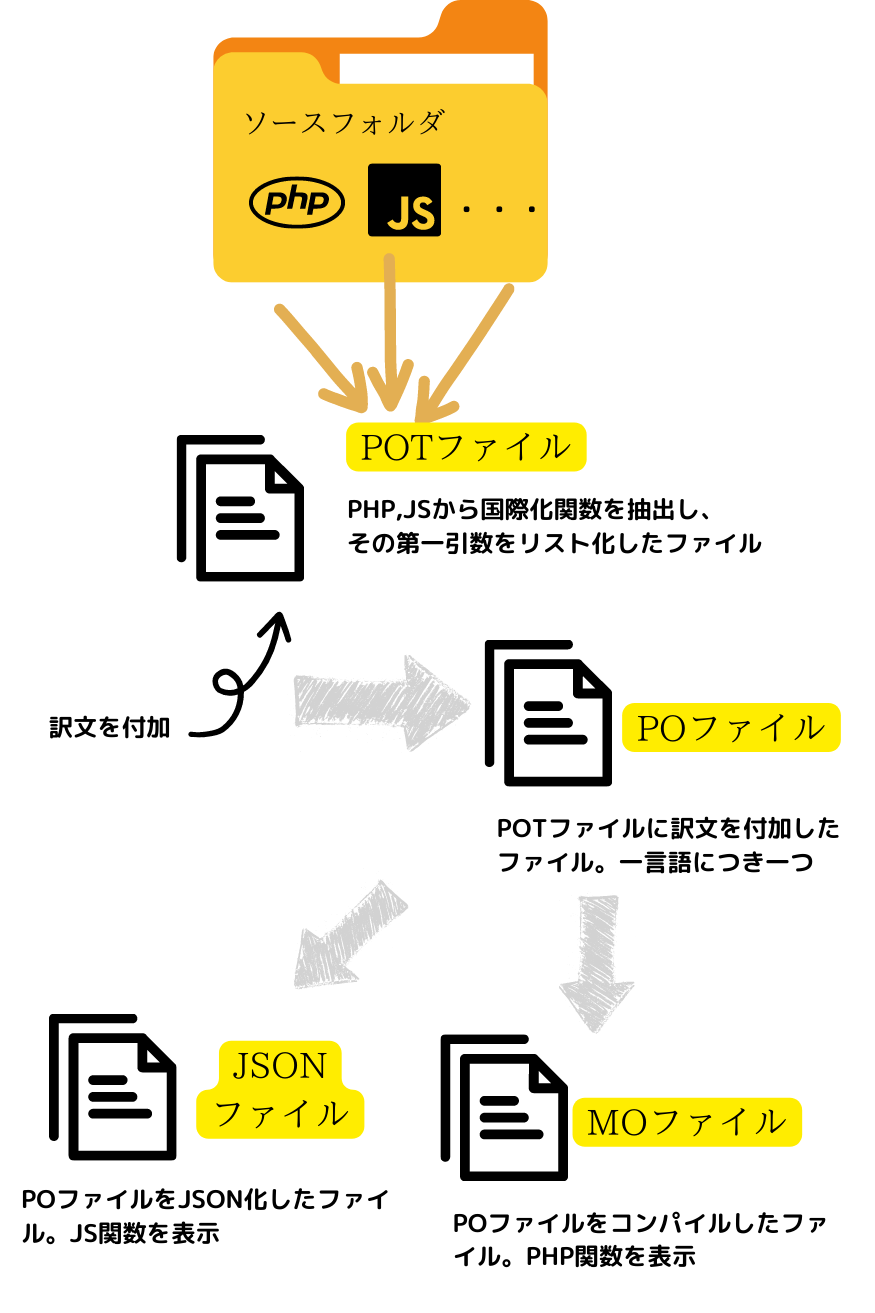
とりあえず、この図で大まかなイメージを掴んでおいてください。
最初の一歩はPOTファイル
まず、POTファイルです。
私は最初POTファイルなるものが何かよくわかりませんでした。いろんな解説記事を見ましたが「POファイルのテンプレート」という表現が多かったです。しかし、これって具体的にイメージしにくいのです。
そこで、私は次のように表現することにしました。
「プロジェクトのソースフォルダからプログラムファイルを検索し、その中から()や_e()などの翻訳関数を抽出し、その第1引数をリスト化したファイル」
厳密さは欠けるように思いますが、どんなファイルか具体的なイメージが湧きやすい気がします。
さらに詳しく説明します。 翻訳関数は引数を2つとります。 第1引数は表示する文字列の原文です。普通は英語でしょうね。 第2引数はテキストドメインです。それってなに? 今の段階ではその説明はちょっと置いておきましょう。POファイルのところで説明します。
とにかく、この関数がプラクラム内で使用されていることが前提になります。POTファイルは、その関数の第1引数、つまり、翻訳すべき原文のリストなのです。そして、それに訳文を入力する「枠」がついていますが、POTファイルの段階では、その部分が空なのです。
なぜ空かというと、それがまさにテンプレートと言われる所以で、そのPOTをもとに日本語訳のついたファイル、中国語訳のついたファイルというように複数のPOファイルを作るためです。
ということで、POTファイルは国際化対応の根幹となるファイルだと思います。これを確実に作ることから始めるべきだと思いました。 Poeditなどの便利なアプリケーションが多くのサイトで紹介されえているのですが、このアプリケーションはPOファイルを生成するためのアプリケーションで、POTファイルは別途用意されていることが前提となっています。しかも、POTファイルなくしてプログラムのソースファイルからいきなりPOファイルを生成する機能ももっています。そのため、初心者が最初にこのアプリケーションを使うと、POTファイルの存在価値を意識しないようになってしまう気がします。これはおすすめしません。まず、POTファイルの作り方を覚えましょう。
WP-CLIのインストール
WP-CLIはWordPressのよくある作業を管理するための開発者向けのコマンドラインツールです。このツールでPOTファイルを作ります。 Poeditでも作れますが、少なくともGutenbergのブロック開発環境においては、WP-CLIを使うことは必須だと思います。私は最初PoeditでPOTを生成したため、かなり遠回りをしました。PoeditはPOファイルを作るものでPOTを作るものではないように思います(有料版は試していないのでわかりません。)。
WP-CLIのインストールは次の手順で簡単にできます。
インストール手順1(SCOOPのインストール)
- PowerShellを管理者権限で開きます。
- 以下のコマンドを実行して、Scoopをインストールします:
Set-ExecutionPolicy RemoteSigned -scope CurrentUser
iex (new-object net.webclient).downloadstring('https://get.scoop.sh')
インストール手順2(WP-CLIのインストール)
- PowerShellを開きます。
- 以下のコマンドを実行して、WP-CLIをインストールします:
scoop install wp-cli
インストールが完了したら、コマンドプロンプトやPowerShellでwp --infoを実行して、正しくインストールされたか確認できます。
POTファイルの生成
対象のブロックのルートディレクトリでターミナルを開いて、次のコマンドを実行します。
wp i18n make-pot ./ languages/itmar_guest_contact_block.pot --exclude=node_modules/*
第1引数./はルートディレクトリ以下のすべてのディレクトリ内のファイルを対象に関数を検索することを意味します。
第2引数は出力対象のPOTファイル名です。ファイル名は何でもよいのですが、テキストドメイン名を使うのが一般的でしょう。--excludeオプションは、検索対象の中から特定のディレクトリを除外するものです。なくてもよいのですが、ブロックの開発環境には多くの場合node_modulesディレクトリがあり、そこには大量のファイルがあるので、検索対象から外しましょう。
ということで実際に出来上がったファイルは以下のようになります。
・・・ #: guest-contact-block.php:163 msgid "Receipt processing completed successfully." msgstr "" #: build/index.js:132 #: src/edit.js:103 #: build/index.js:116 msgid "Inquiry information notification email" msgstr "" ・・・
このコードはPOTファイルの一部です。msgidが原文の見出しで、msgstrが訳文の見出しです。訳文は空になっていますね。
#:以下は翻訳関数があったファイルとその行番号です。この情報が非常に重要なのです。これがないと、JSONファイルの作成のところで大きくつまづきます。
つづいてPOファイルの作成
ここでPoeditというアプリケーションを使います。 インストール方法は簡単で、次の公式ページからダウンロードしてそのファイルをダブルクリックするだけです。 https://poedit.net/download/
POファイルの作成手順はスクリーンショットで説明します。
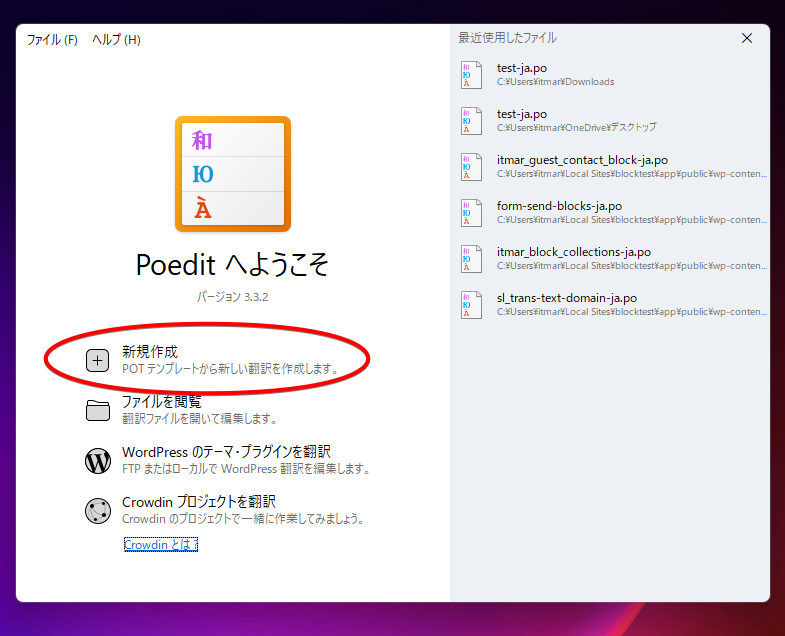
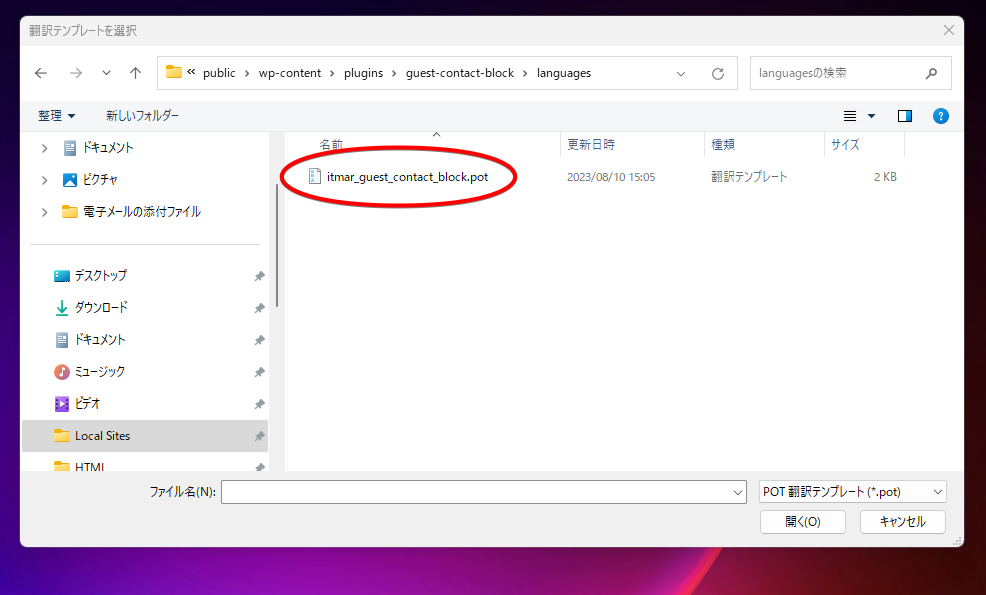
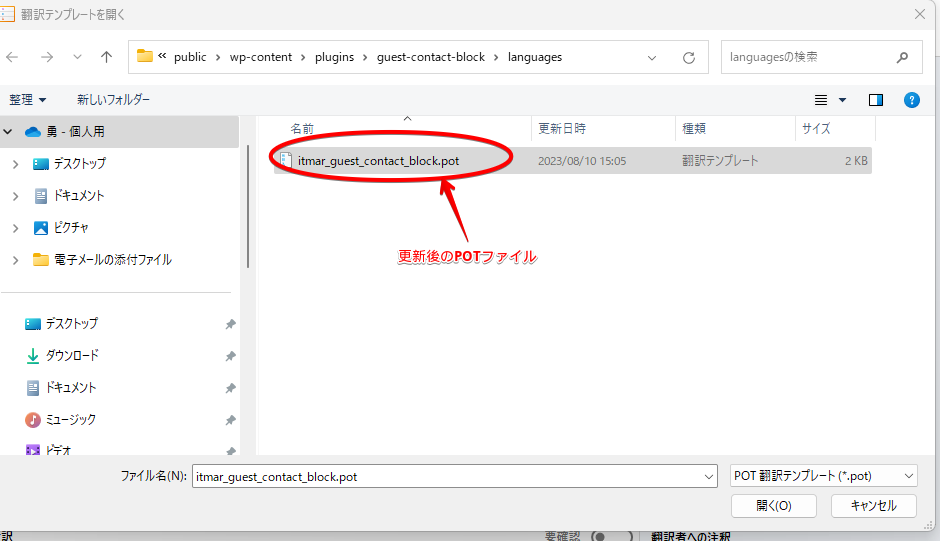
WP-CLIで作成したPOTファイルを選択します。
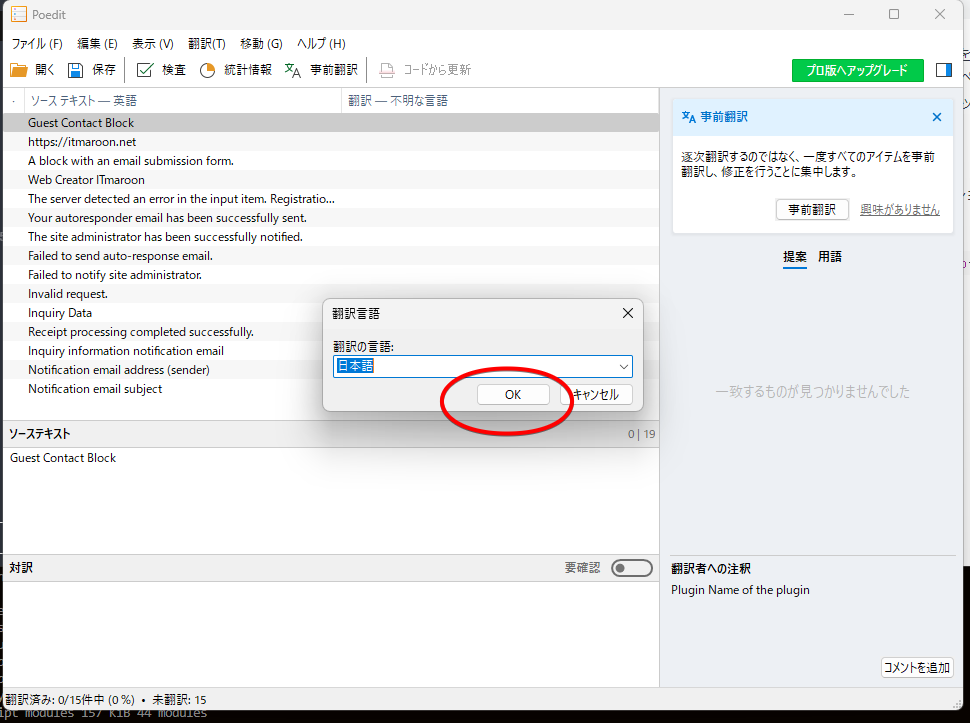
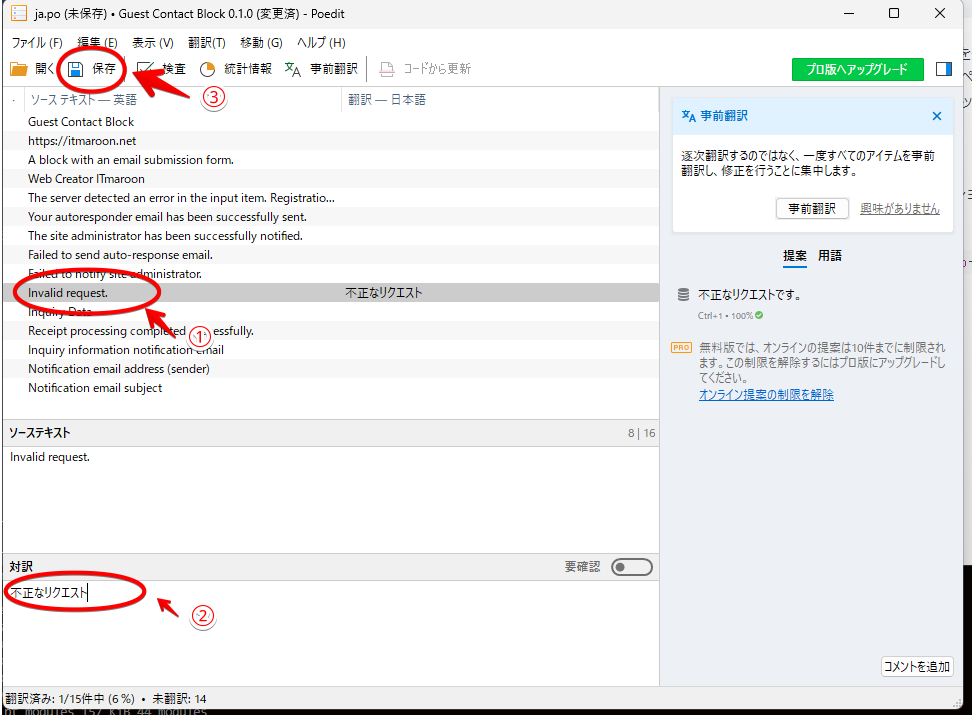
①で入力項目を選択し、②で訳文を入力、③で保存です。
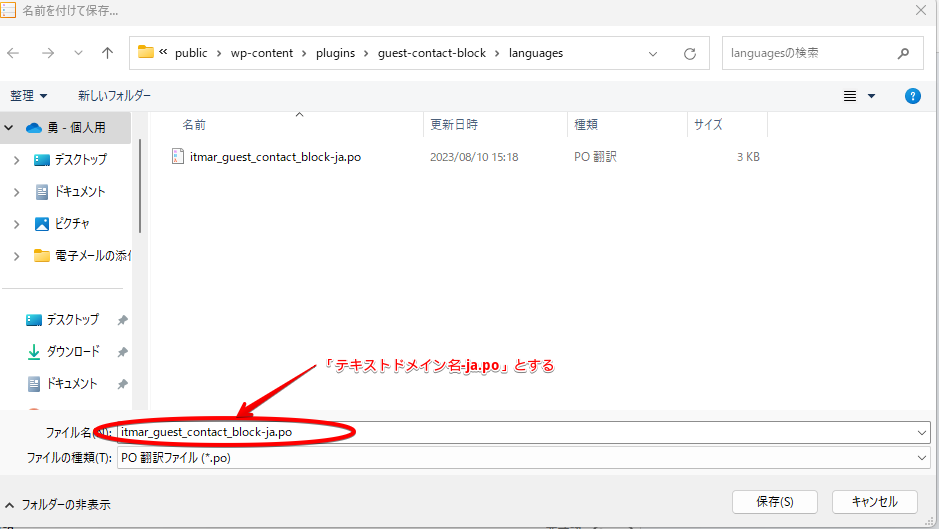
このファイル名は重要です。デフォルトでは「ja.po」となっているので、その前に「テキストドメイン-」と入れます。
ここでテキストドメインについて説明します。
テキストドメインは翻訳関数__()等の第2引数に設定すると説明しました。そうすることによって翻訳関数はそのテキストドメインの文字列を含むファイル名を持つファイルから、第1引数にセットした原文の文字列から訳文を検索するようになっているのです。つまり、
__("Notification email subject", 'itmar_guest_contact_block')
という関数があるとするとitmar_guest_contact_blockという名前を含むファイルを探し、さらに、第1引数の文字列と一致する訳文を探して表示するのです。ですから、ここでつけるファイル名は重要です。これを間違うと訳文は表示されません。
これで保存すれば無事にPOファイルは出来上がりです。
MOファイルはなんのためにある?
ではMOファイルは何のためにあるのでしょう。 先ほど翻訳関数がテキストドメイン名のついたファイルを探しにいくといいましたが、実際に探しにいくのはPOファイルではなく、MOファイルなのです。そして重要なのはこのMOファイルはPHPの翻訳関数の訳文を表示させるファイルだということです。 Javascriptの翻訳関数による訳文はMOルがあっても表示されません。
とりあえず、ここではMOファイルによる訳文の表示に絞って解説していきます。 MOファイルはPOファイルをバイナリ形式でコンパイルしたファイルで、先ほどPoeditでPOファイルを保存しましたが、そのとき自動的に生成されるようになっています。ただし、これは設定で生成されないようにもできるので、設定されているかどうかは確認しておきましょう。 Poeditを立ち上げて[ファイル]ー[設定]で次のダイアログが出るので、そこで確認できます。
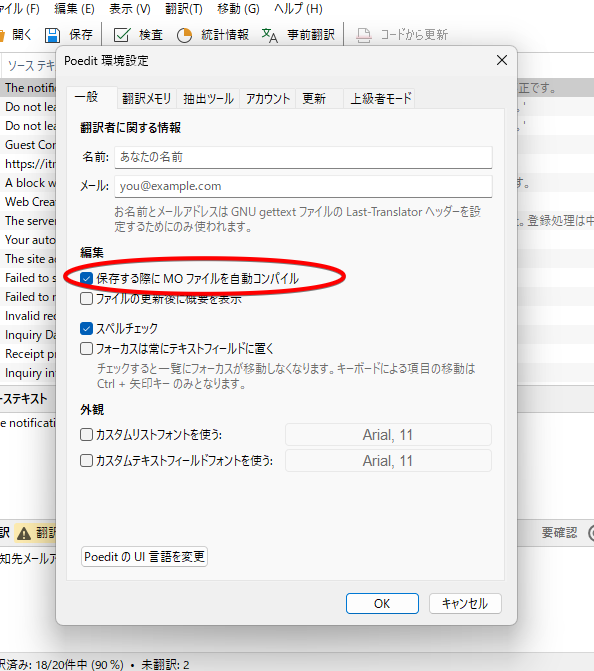
load_plugin_textdomainによる読込
そしてさらにブロックのエントリポイントのPHPファイルに次のように記述しなくてはいけません。
function itmar_contact_block_block_init() {
・・・
//PHP用のテキストドメインの読込(国際化)
load_plugin_textdomain( 'itmar_guest_contact_block', false, basename( dirname( __FILE__ ) ) . '/languages' );
}
add_action( 'init', 'itmar_contact_block_block_init' );
WordPressのinitアクションフックでload_plugin_textdomain実行するわけです。第1引数はテキストドメイン、第3引数はMOファイルの保存フォルダへの相対パスです。今回はブロックのルートディレクトリ直下のlanguagesフォルダを指しています(第2引数はあまり気にせずfalseでいいようです。)。
これでPHPで記述された翻訳関数の部分は訳文が表示されます。
このように自分で任意のフォルダにMOファイルを保存した場合はload_plugin_textdomainで、その場所を指定する必要がありますが、.\wp-content\languages\pluginsというフォルダに保存すれば、load_plugin_textdomainでの指定は必要ありません。
ただし、このフォルダはプラグインの外にあるフォルダなのでプラグインをインストールしただけでは保存することができず、ユーザーに一手間かけさせることになります。できれば、そうしない方がいいのではないかと思います。
PHPのコメントヘッダー内の翻訳
プラグインのエントリポイントのPHPファイルにはコメントヘッダーが付いていて、これがあることでプラグイン名等が表示されます。
/** * Plugin Name: Guest Contact Block * Plugin URI: https://itmaroon.net * Description: A block with an email submission form. * Requires at least: 6.1 * Requires PHP: 7.0 * Version: 0.1.0 * Author: Web Creator ITmaroon * License: GPL-2.0-or-later * License URI: https://www.gnu.org/licenses/gpl-2.0.html * Text Domain: itmar_guest_contact_block * Domain Path: /languages */
こんな感じになっていますが、WP-CLIでPOTファイルを作ると、次のように抽出してくれます。
#. Plugin Name of the plugin msgid "Guest Contact Block" msgstr "" #. Plugin URI of the plugin msgid "https://itmaroon.net" msgstr "" #. Description of the plugin msgid "A block with an email submission form." msgstr "" #. Author of the plugin msgid "Web Creator ITmaroon" msgstr ""
この部分については翻訳関数がセットされていなくても、POファイルに訳文を入れてMOファイルを生成するだけで翻訳されます。
JSONファイルによるJS関数の翻訳
ここまでの手順も相当複雑でしたがPOT、PO、MOの各ファイルの機能を理解していれば、そんなに苦労せずにたどり着けるのではないかと思います。 問題はここからなのです。 なかなか、正確に説明してくれている記事にも巡り合えず、ChatGPTの答えも不正確でした。
そもそも、PHPの関数とJS(JavaScript)の関数で翻訳の仕組みが違い、しかも、MOファイルではなくJSONファイルを用意しないといけないなんて思いもしませんでした。 それに気付くのにも時間がかかりました。 ブロック開発では訳文を表示させたいのは、ほとんどがJSの関数で作られています。それが表示されないと意味がありません。
それはともかく、コードとしては次のようになっています。
import { __ } from '@wordpress/i18n';
・・・
return(
・・・
<TextControl
label={__("Notification email subject", 'itmar_guest_contact_block')}
・・・
/>
・・・
)
PHPと違うのは関数のimportが必要であるという点だけです。 また、JSONファイルを作ること自体も簡単です。プラグインのルートディレクトリで次のコマンドを実行します。
wp i18n make-json languages/ --no-purge
これでプラグインのルートディレクトリ直下のlanguagesフォルダからpoファイルを探し出してjsonファイルが生成されます。
これで訳文が表示されるなら簡単なのです。
しかし、これからが苦難の始まりです。
wp_set_script_translationsによるJSONファイルの指定(失敗談)
PHPではload_plugin_textdomainでMOファイルを読み込みましたが、JSONファイルにおいてもそれと同様のプロセスが必要です。
wp_set_script_translations( $script_handle, 'itmar_guest_contact_block', plugin_dir_path( __FILE__ ) . 'languages' );
このコードをload_plugin_textdomainと同様にinitアクションフックで実行します。
第2引数がテキストドメインで、第3引数はJSONファイルが保存されているフォルダへの相対パスです。
問題は第1引数です。これはスクリプトハンドルと呼ばれる文字列です。
WordPressのテーマでもプラグインでも外部のライブラリを読み込むときはwp_enqueue_scriptというコマンドを使います。このコマンドの第1引数で指定するのがスクリプトハンドルです。wp_enqueue_scriptで指定するのは他のwp_enqueue_scriptで使用するスクリプトハンドルと重複しない任意の文字列でよいのですが、wp_set_script_translationsで使うスクリプトハンドルは、すでにwp_enqueue_script等の登録コマンドで使用されている文字列でないとダメなのです。
平たく言うと使用実績があるスクリプトハンドルということですね。それがないなら、あらかじめダミーのスクリプト用意してwp_enqueue_script等の登録コマンドを実行しておかなければいけないのです。
コードとしては次のようになります。
wp_enqueue_script(
'itmar_script-handle',
plugin_dir_url( __FILE__ ) .'dummy.js',
array( 'wp-blocks', 'wp-i18n', 'wp-element', 'wp-editor' ),
'1.0.0',
true
);
wp_set_script_translations(
'itmar_script-handle',
'itmar_guest_contact_block', plugin_dir_path( __FILE__ ) . 'languages'
);
そんな無駄なエンキューしないといけないのかと思うのですが、これでwp_set_script_translationsは機能してくれているはずなのです。
とおもって、ブロックをリロードして表示を確認しました。
・・・英語のままです。なぜ???
かなり、時間をかけて調べました。すると、JSONファイルのファイル名の形式は
${domain}-${locale}-${handle}.jsonまたは${domain}-${locale}-${md5}.jsonと書いてある記事を見つけました。
WP-CLIが生成したファイル名はitmar_guest_contact_block-ja-bb1d7dea005e67527e728d4801f74b61.jsonで後者の形式です。では、前者の形式にしてみようと思い、次のようにリネームしました。
itmar_guest_contact_block-ja-itmar_script-handle.json
これで再度チャレンジ! 訳文が表示されました!やったー!! リネームするのは面倒だけど、これでなんとかなるならこれでいいやと思いました。
これで他のブロックも同じように国際化対応しようと思い、POファイルを作り、WP-CLIを実行しました。 すると、さっきとは違ってJSONファイルが複数出来上っています。これってどういうことかほんとに悩みました。
調べた結果、WP-CLIはPOファイルから翻訳関数があったファイル名を読み取り、その名前をmd5ハッシュに変換してJSONのファイル名にしていました。そのため、POファイルに複数の元ファイル名が記録されていると、その数だけファイルが生成されます。 こうすることでブラウザで表示されるファイル以外の翻訳ファイルは読みこまずパフォーマンスを向上させる仕組みということもわかりました。 しかし、これをされると先のリネーム作戦は実行できません。同一フォルダに同一名のファイルは保存できないからです。 結局、フリダシに戻りました。
wp_set_script_translationsによるJSONファイルの指定(ようやく成功)
それから相当色々試してみました。po2jsonというパッケージも試しましたが、今一つしっくりきません。 その紆余曲折を語ると大変なので、最終的な結論だけ紹介します。 コードを示します。
function itmar_contact_block_block_init() {
$script_handle = 'text_domain_handle';
// スクリプトの登録
wp_register_script(
$script_handle,
plugins_url( 'build/index.js', __FILE__ ),
array( 'wp-blocks', 'wp-element', 'wp-i18n', 'wp-block-editor' )
);
//ブロックの登録
register_block_type( __DIR__ . '/build',
array(
'editor_script' => $script_handle
)
);
// その後、このハンドルを使用してスクリプトの翻訳をセット
wp_set_script_translations( $script_handle, 'itmar_guest_contact_block', plugin_dir_path( __FILE__ ) . 'languages' );
//PHP用のテキストドメインの読込(国際化)
load_plugin_textdomain( 'itmar_guest_contact_block', false, basename( dirname( __FILE__ ) ) . '/languages' );
}
add_action( 'init', 'itmar_contact_block_block_init' );
このコードはこの公式ページを見て考え付きました。
やっぱり、最後は公式ページですね。
コードの解説です。
①「// スクリプトの登録」のセクションではwp_register_scriptというコマンドを使っています。これは先に紹介したwp_enqueue_scriptと違ってスクリプトファイルをエンキューせず、スクリプトハンドルだけを登録するコマンドです。これでスクリプトハンドルを確保します。
②「//ブロックの登録」セクションではregister_block_typeでブロックを登録しますが、その時の登録情報の一つであるeditor_scriptを①で確保したスクリプトハンドルに上書きしています。
③「// その後、このハンドルを使用してスクリプトの翻訳をセット」のセクションでは、そのスクリプトハンドルを使って、wp_set_script_translationsを実行しているのです。
つまり、${domain}-${locale}-${md5}.jsonの形式のファイルが機能するためには、wp_set_script_translationsの第1引数は、ブロックのeditor_scriptに登録されたスクリプトハンドルである必要があるということです。editor_scriptに登録されたスクリプトハンドルというのはbuild/index.jsをロードするものでないといけません。それが上記のコードのwp_register_scriptというわけです。
@wordpress/create-blockで作ったブロックのプロジェクトではブロックの登録はblock.jsonの情報に基づいて行われるようになっています。その中では"editorScript": "file:./index.js",となっています。wp_register_scriptは、それと同等の働きをするということがわかりました。その上でスクリプトハンドルを使い回すことができるようにするというのが、今回の成功への道のりだったと言えます。
もう一点忘れていけないのはPOファイルの翻訳関数の存在していたファイル情報にbuild/index.jsが含まれていないければいけないということです。src/edit.jsだけでは表示されません。これはPOTファイルの生成に関連するもので、PoeditでPOTファイルを生成するとうまくいきませんでした。
POファイルの更新方法
最後にPOファイルの更新方法を紹介します。これはPoeditの力を借りるのが一番だと思います。 POファイルの更新というのは、ソースファイルの更新により、翻訳関数の追加、削除、内容の変更が起こったとき必要になります。 これはPOTファイルを更新する必要があるので、ソースファイルを更新したら、次のWP-CLIコマンドを実行します。
wp i18n make-pot ./ languages/itmar_guest_contact_block.pot --exclude=node_modules/*
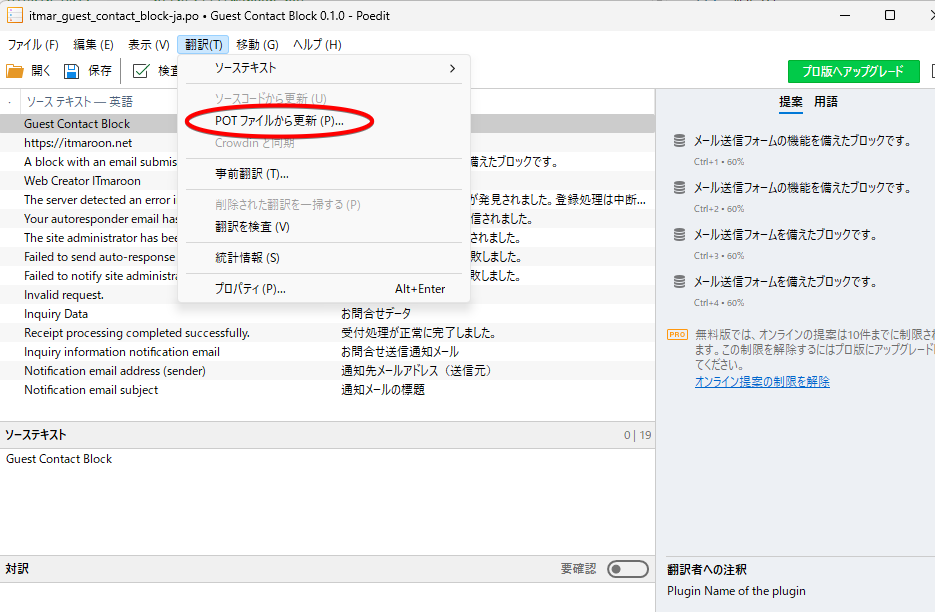
それからPoeditを立ち上げます。
更新したいPOファイルを選択して、開いてから「POTファイルから更新...」を押します。
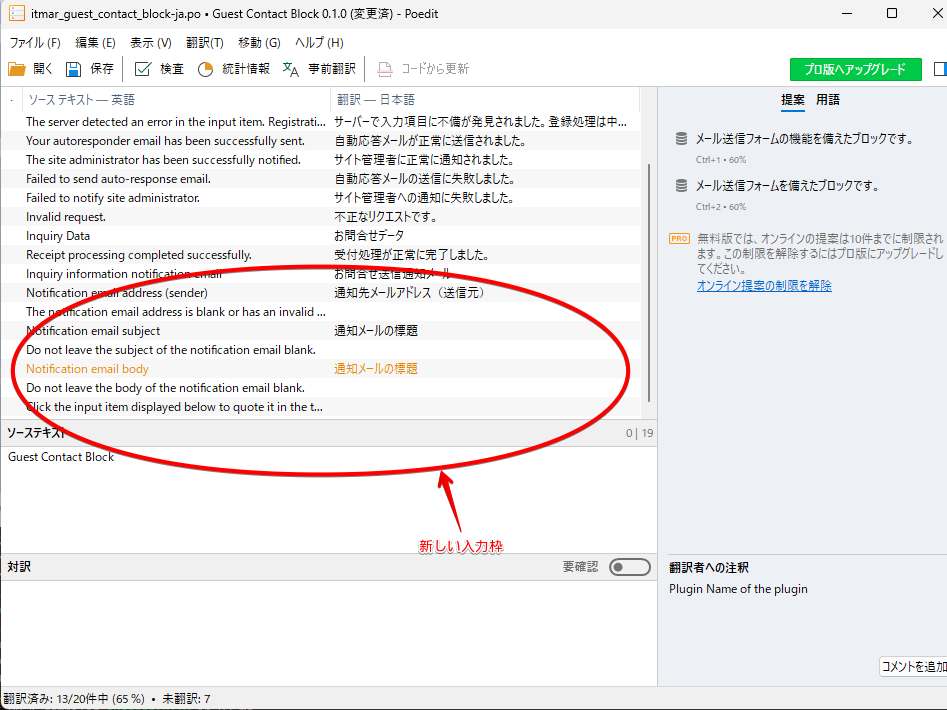
このように新しい入力枠ができています。ここに入力していくことで更新することができます。
この作業が終わってPOファイルを保存すればPoeditがMOファイルは更新してくれます。 しかし、JSONファイルは更新してくれないので、最後に次のコマンドを実行するのを忘れないで下さい。
wp i18n make-json languages/ --no-purge
長いブログになりましたが、以上にしたいと思います。 これから国際化対応をする方には、重要な情報を詰め込んだつもりです。お役に立てれば光栄です。 最後までお読みいただきありがとうございました。
最初の一歩はRichTextの設置
ブロックの機能としてテキストを編集することができるというのは、最も基本的な機能だと思います。 そこで、今回はブロック制作を始められた方向けに、RichTextコンポーネントというWrodpressが用意してくれているコンポーネントの使い方を説明したいと思います。
この記事の前提事項
この記事は、npx @wordpress/create-blockでブロックの開発環境が構築できていることを前提としています。wordpress/create-blockでの環境開発の構築方法については、他の記事をご覧ください。
当ブログでは次のような記事を公開しているので、良かったら参考にしてください。
同一プラグインで複数ブロックを仕込む方法
edit.jsのコーディング
編集画面を描画するためのedit.jsを次のように変更してください。
import { __ } from '@wordpress/i18n';
import { useBlockProps, RichText, } from '@wordpress/block-editor';
import './editor.scss';
export default function Edit(props) {
const { attributes, setAttributes }=props
const blockProps = useBlockProps();
const { content } = attributes;
const onChangeContent = ( newContent) => {
setAttributes( {content:newContent} )
}
return (
<div { ...blockProps }>
<RichText
tagName="p"
onChange={ onChangeContent }
value={ content }
placeholder={ __( 'Write your text...' ) }
/>
</div>
);
}
edit.jsをすべて削除して、その後に、コピペして大丈夫です。
value={ content }
onChange={ onChangeContent }
の部分に着目してください。
この2つでブロックが持つ情報であるattributesの情報を取得・更新しています。上がattributes情報の取得、下が更新です。
そしてcontentという変数には
const { content } = attributes;でattributesオブジェクトを分割代入しています。
block.jsonの編集
こういうことをできるようにするためには、ブロックにattributesという情報を持たせ、さらにその中にcontentという情報をもたせる'器'を用意してやる必要があります。しかし、現時点でのブロックは、そのような'器'は持っていません。 この'器'を用意するのがblock.jsonの役割です。 block.jsonに
"attributes": {
"content": {
"type": "string",
"source": "html",
"selector": "p"
}
},
と入れてやりましょう。これを入れる場所はどこでもよいのですが、私は習慣的に
"supports": {
"html": false
},
のあとに挿入するようにしています。
これでブロックが'器'をもちました。
これでプロジェクトをビルドすれば、ブロックエディタの画面は次のようにテキストを入力できるようになります。
save.jsの編集
しかし、編集画面にRichテキストコンポーネントは現れて、文字の入力や編集ができるようになっても、本番のWebサイト(これをフロントエンドという呼び方をします。)には、その文字は表示されません。これを表示するためにはsave.jsを手入れしないといけないのです。 これはどんなブロックでも同じです。編集画面とフロントエンドは別々に作るということを覚えておいてください。
save.jsには次のように記述します。
import { useBlockProps, RichText } from '@wordpress/block-editor';
export default function save({ attributes }) {
const { content } = attributes;
const blockProps = useBlockProps.save();
return (
<div { ...blockProps }>
<RichText.Content
tagName="p"
value={ content }
/>
</div>
);
}
これももとのsave.jsをすべて削除して、その後にコピペして大丈夫です。
こちらは描画するだけなので
value={ content }
しか記述がありません。これでプレビュー画面にも描画されます。
ここで、2点注意事項です。
1点目はblock.jsonに
"attributes": {
"content": {
"type": "string",
"source": "html",
"selector": "p"
}
}
と記述しましたが、その中で"source": "html"の記述があります。これがあるとsave.jsにおいてp要素にcontentの内容を描画するように指定しないとエラーになったり保存されなかったりするということです。ですから、edit.jsの手入れだけしてsave.jsの手入れをしないと編集画面にもcontentの内容が表示されないことになります。 2点目はsave.jsではRichTextではなく、RichText.Contentを返してやる必要があるということです。これを誤るとエラーを起こします。 両者の違いをChatGPTに聞いてみると
RichTextはテキストを編集するためのリッチテキストエリアを提供し、RichText.ContentはRichTextコンポーネントによって編集されたテキストの実際の内容を表し、リッチテキストエリアに表示された通りのテキストを取得します。
ということでした。 内容を編集する機能はHTMLの内容を動的に変化させるということです。ここでWordpressの基本を思い出してください。フロントエンドに出力される内容はサーバーで生成されるものです。それとフロントエンドを描画する機能をもつsave.jsが生成するHTMLは違うものであってはいけないのです。当然、フロントエンドで文字の編集ができるようにすることはできません。 これがフロントエンドの描画(レンダリング)と編集画面のレンダリングの大き違いです。
RichText機能のカスタマイズ(おまけ)
最後におまけとしてRichTextの機能を簡単にカスタマイズする方法を紹介しておきます。 それはブロックコントロールにFormatに関する設定を行うボタンを表示させるものです。
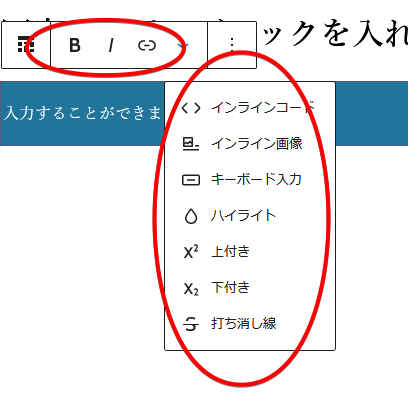
このようにブロックコントロールには様々なFormatツールが設置されていますが、allowedFormatsに'core/bold'や'core/italic'という文字列を配列で渡すことで制御することができます。
<RichText
tagName="p"
onChange={onChangeContent}
allowedFormats={['core/bold', 'core/italic', 'core/link']}
value={content}
placeholder={__('Write your text...')}
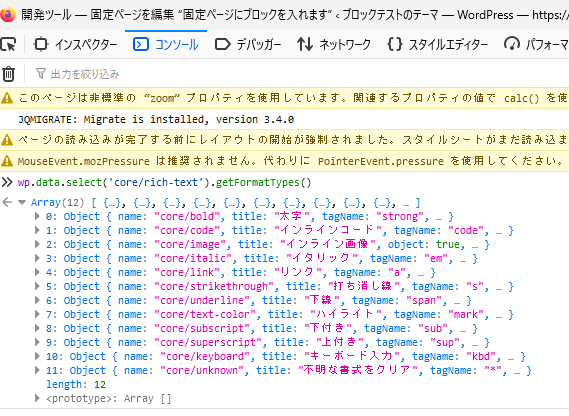
/>
この文字列はRichTextを表示しているブラウザで開発ツールのコンソールを開き、wp.data.select( 'core/rich-text' ).getFormatTypes();と入力すると配列が表示されます。